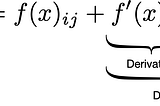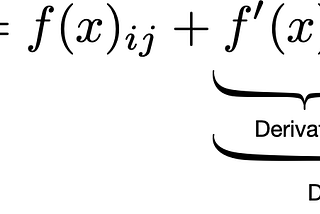Introduction to residual correctionBetter formated version (LaTex) of this post on GhostOct 14, 2023Oct 14, 2023
Gradient descent under harmonic eigenvalue decayBetter formatted version on ghost (due to Latex support)Feb 16, 2023Feb 16, 2023
Critical batch-size and effective dimension in Ordinary Least SquaresNote: a better formatted version (due to lack of LaTeX support on medium) is hereJan 30, 2023Jan 30, 2023
optimal learning rate for Gradient Descent on a high-dimensional quadraticA better formatted version of this article is on Ghost, which has proper Latex support…Dec 27, 2021Dec 27, 2021
How many matmuls are needed to compute Hessian-vector products?Suppose you have a simple composition of d dense functions. Computing Jacobian needs d matrix multiplications. What about computing Hessian…Dec 15, 2021Dec 15, 2021
How to do matrix derivativesSuppose you have the following scalar function of matrix variable W.Jul 9, 20211Jul 9, 20211
Using “Evolved Notation” to derive the Hessian of cross-entropy lossI was recently reminded of a lesson learned at Stephen Boyd’s Convex Optimization class at Stanford a few years ago, back when Google was…Aug 30, 2019Aug 30, 2019
ICLR Optimization papers IIISelf-Tuning Networks: Bilevel Optimization of Hyperparameters using Structured Best-Response FunctionsJun 25, 20191Jun 25, 20191